



PreSonus’s new Quantum audio interfaces feature inputs that were co-developed with Fender
Auto Gain, Loopback and Reamping features are also in the mix
MusicRadar's up-to-date news coverage of the latest musical instruments, music equipment, music tech and trade events
Auto Gain, Loopback and Reamping features are also in the mix

Co-writer Espen Lind on how he got the ukulele back into the charts – after saving the song with it

"For them it was business as usual"

How extreme stress birthed the iconic heart of John 'Cougar' Mellencamp's smash hit

"It’s amazing what you can do if you’re put on the spot", said Luthier Dave Rusan

Yep, that’s right: she’s never seen Back To The Future
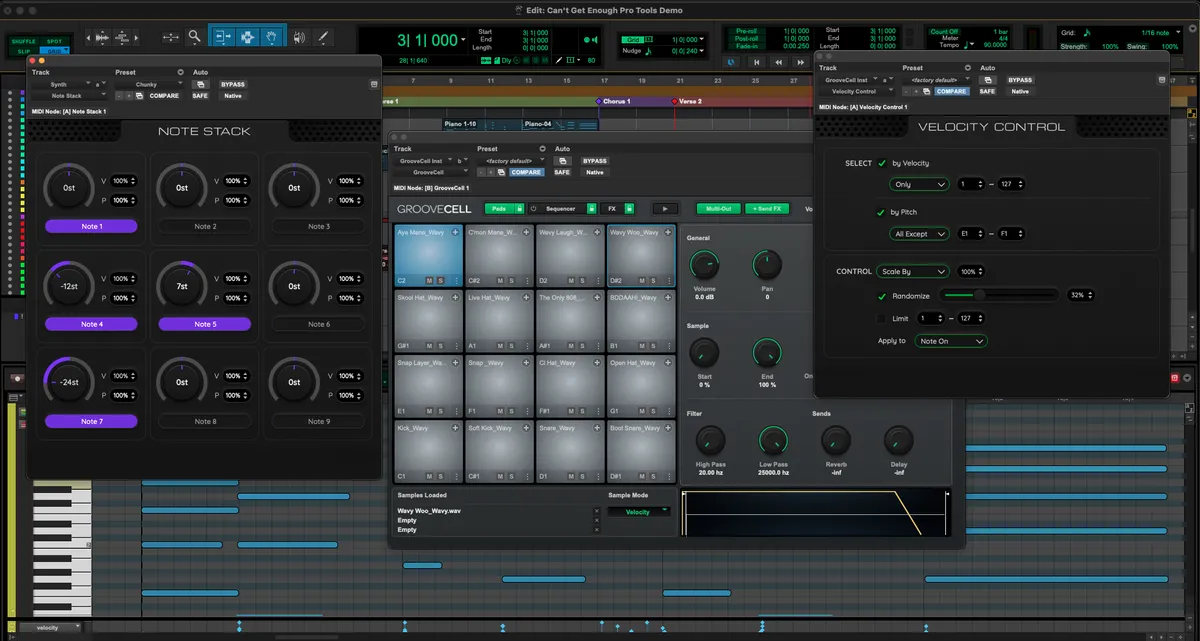
In the next edition of an ongoing series exploring why music-makers choose their DAWs, Rob Speight talks us through the reasons behind his predilection for Pro Tools

It’s a Minimoog, but not as you know it

The late King Of Twang remembered his signature song with us back in 2011

"It’s funny because we sound like a really bad tribute band for the first three or four run-throughs on these things"

NI scraps Komplete Now and launches three-tier subscription service for Komplete content and plugins from NI, iZotope, Brainworx

Everything you wanted to know about raising your vocal game

Top-dollar gets you a dual-OLED display, but you can now get a lot of good stuff for significantly less

Events will take place across Shoreditch, London for a week in June next year

Ritenour says nobody on the planet could play like BB King did, and the King of the Blues' trademark vibrato was all the more remarkable on such an uncompromising guitar setup

"I've been tweaking them like crazy" Slash says of his ongoing battles with the "necessary evil" of using in-ears
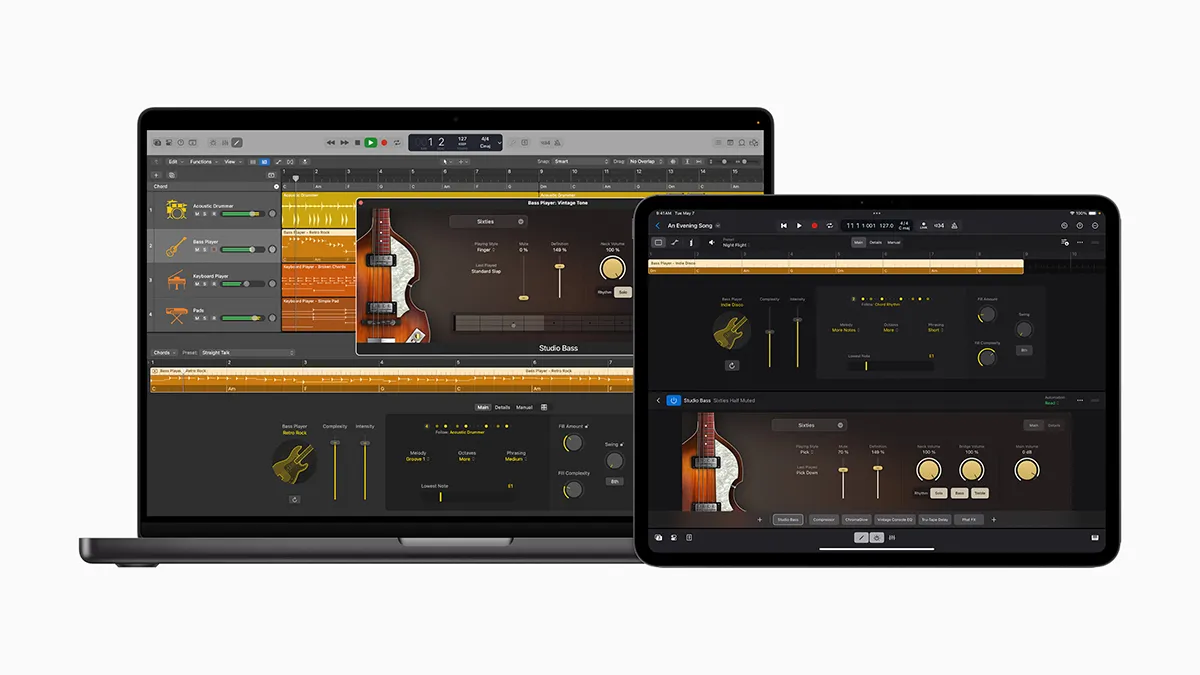
New versions of the mobile and desktop versions of the DAW are on the way

Whether you're looking to apply some vintage vocoder to your track or to Prismize-up your vocal, this buyer's guide showcases the best plugins to consider – for everything from a vintage to a super-modern sound…

Mike Fortin does not like digital amp modelling but he likes this one, and it comes fully equipped for downtuned metal guitar mass destruction with all-new 9-band graphic EQ, transpose and doubler

